Warum liefert Claude manchmal brillante Ergebnisse und manchmal frustrierend schlechte? Die Antwort liegt oft nicht im Modell selbst, sondern in etwas, das die meisten Entwickler unterschätzen: dem Kontext.
In diesem Artikel beschäftigen wir uns mit dem Thema Kontext von LLMs. Einige Beispiele und Ausführungen beziehen sich speziell auf Claude Code, aber die Konzepte gelten für alle ähnlichen Tools und zum großen Teil auch für LLMs allgemein.
Was ist LLM-Kontext überhaupt?
Grundkonzept von LLMs
In ihrer Grundfunktion sind LLMs “nur” Next-Token-Predictors, die erhebliche Mengen an RAM benötigen. Als Funktion ausgedrückt sagen sie für ein gegebenes Prefix p ein nächstes (wahrscheinlichstes) Token t voraus.
Wenn man mit einem LLM interagiert, hat dieses kein Gedächtnis, lernt durch die Interaktion nichts und es wird nicht mal der Zustand zwischen den Anfragen behalten.
Ein häufig herangezogener Vergleich ist:
Ein neuer Mitarbeiter mit extrem viel Allgemeinwissen, aber absolut keinem “Domänenwissen”… und dummerweise auch ohne jegliche Fähigkeit sich etwas Neues zu merken.
Was macht den Kontext aus
Nun produzieren LLMs allerdings mehr als ein Output-Token pro Anfrage, man kann sich mit ihnen “unterhalten” und sie “merken” sich auch, um was es in der Unterhaltung geht. Dies liegt am bereits erwähnten Präfix. Dieses enthält die komplette Konversation und nicht nur die aktuelle Anfrage und bildet damit den Kontext:
Kontext = Präfix = alle (bisherigen) Informationen in einer einzelnen Anfrage
prefix := (system prompt, user message 1, llm reply 1, ..., user message n-1, llm reply n-1, user message n) -> generate llm reply n
Für Claude Code spezifisch sieht das so aus:
- System-Prompt (von Anthropic, verborgen)
- TODO-Liste
- CLAUDE.md-Datei(en) - Projekt- und Benutzer-Gedächtnis
- Gesprächsverlauf (alle vorherigen Nachrichten in der Sitzung)
- Tool-Aufrufe und ihre Ergebnisse
- Aktueller Prompt
- Tool-Beschreibungen
Dies sieht für andere Anbieter ähnlich aus mit anderen system prompts und Namen für “memory files”.
Kontext wächst stetig
Der Kontext wird mit jeder Interaktion in einer Sitzung länger! Für viele aktuelle Modelle liegt die Kontextgröße zwischen 200k bis 1 Mio Tokens (von nur wenigen Tausend Tokens vor ca. 2 Jahren). Jede neue Nachricht, jeder Tool-Aufruf und jedes Ergebnis erweitern den Kontext, daher hört sich 200k Tokens erstmal nach viel an, kann aber durchaus schnell aufgebraucht sein.
Einschub: Was sind überhaupt Tokens?
Tokens sind die kleinsten Verarbeitungseinheiten eines LLMs. Als Faustregel gilt: 1 Token ≈ 1 Silbe oder ein kurzes Wort. Ein einfacher Satz mit 10 Wörtern verbraucht etwa 13-15 Tokens. Man sollte sich also bewusst sein, dass man wesentlich mehr Tokens verbraucht, als man Wörter schickt. Allerdings verbraucht man auch wesentlich weniger Tokens, als es Zeichen in der Nachricht gibt.
Kontext-Qualität ist kritisch
Für komplexere Aufgaben ist also die Kontextqualität einer der wichtigsten Faktoren.
Der optimale Kontext muss ALLE drei Eigenschaften haben:
- Hat ALLE Informationen, die das LLM benötigt
- Hat KEINE logischen/internen Widersprüche
- Ist MINIMAL / So kurz wie möglich
Kontext-Probleme
Durch die Arbeit mit LLMs haben sich folgende Probleme herauskristallisiert:
Context Rot (Kontext-Verfall):
Im Allgemeinen verschlechtert sich die Output-Qualität des LLMs je länger eine Session andauert. Der Kontext “verwässert” mit zunehmender Länge und das LLM beachtet frühere Informationen nicht mehr oder es schleichen sich mehr Inkonsistenzen ein und Anweisungen werden ignoriert.
Um das wieder mit dem neuen Mitarbeiter zu vergleichen: Dieser vergisst quasi nicht nur nach jedem Gespräch, sondern nach jeder Antwort. Um dem vorzubeugen, gibt man ihm jedes Mal ein Protokoll des Gesprächs mit (der Kontext). Je länger dieses ist, desto größer die Chance, dass relevante Informationen “unter den Tisch fallen”.
Context Anxiety (Kontext-Angst) (spezifisch für Sonnet 4.5):
Claude Code weiß, wieviel Kontext noch verbleibt und versucht eine Aufgabe noch rechtzeitig zu erledigen. Dies führt häufig zu schlampiger Arbeit mit mangelhaften Ergebnissen. Ähnlich wie bei einem Studenten, der in den letzten 5 Minuten einer Prüfung noch eine Aufgabe mit 30 Minuten Bearbeitungszeit angeht.
Context Engineering vs. Prompt Engineering
Der Begriff Prompt Engineering ist sicherlich vielen bekannt, bei der Arbeit mit AI-Agenten muss man aber noch mehr – den gesamten Kontext – im Auge behalten und effektiv aufbauen und managen:
Prompt Engineering (Einzelabfragen):
- System-Prompt + Benutzernachricht → Assistenten-Antwort
- Einfach, einmalige Interaktionen
Context Engineering (für Agenten):
- System-Prompt + Memory-Dateien + Docs + Tools + Domain-Knowledge + Umfassende Instruktionen + Nachrichtenverlauf
- Kuration: was einschließen, was ausschließen
- Verwaltet über mehrere Interaktionen
- Kritisch für Agentenqualität
Einen guten ausführlichen Überblick zu dem Thema bietet Effective Context Engineering for AI Agents von den Claude-Machern.
Optimalen Kontext aufbauen
Nachdem wir nun wissen, was der Kontext ist und welche Probleme auftreten können, hier einige praktische Tipps, den eigenen Kontext möglichst effektiv zu verwalten.
1. CLAUDE.md - Projekt-Gedächtnis
CLAUDE.md-Files sind automatisch geladener Kontext für jede Anfrage, um grundlegende, immer relevante Informationen zu klären. Dabei werden verschiedene Typen unterschieden:
- Projekt-Gedächtnis:
./CLAUDE.md(geteilt, sollte in Git eingecheckt werden)- Lädt auch aus übergeordneten Verzeichnissen und Unterverzeichnissen bei Bedarf
- Lokales Projekt-Gedächtnis:
CLAUDE.local.md(.gitignored, persönlich) - Benutzer-Gedächtnis:
~/.claude/CLAUDE.md(immer geladen, alle Projekte)
Tipp: CLAUDE.md kann andere Dateien importieren. Füge @path/to/file.md zur ./CLAUDE.md hinzu, um zusätzliche Dateien beim Start zu laden.
Best Practices für CLAUDE.md:
- Nutze das
/init-Kommando zum Erstellen der initialenCLAUDE.md - Überprüfe und korrigiere Halluzinationen/Fehler
- Ziel: So kurz wie möglich, aber so umfassend wie nötig
- Widersprüche sind Gift für die Output-Qualität
- Einschließen: Struktur, Build-Kommandos, Test-Prozeduren, Guidelines
- Ausschließen: nebensächliche Details
- Aktualisiere
CLAUDE.mdso oft wie nötig!
Gute Instruktionen am Anfang sind sehr wichtig für die Output-Qualität, verdeutlicht in:
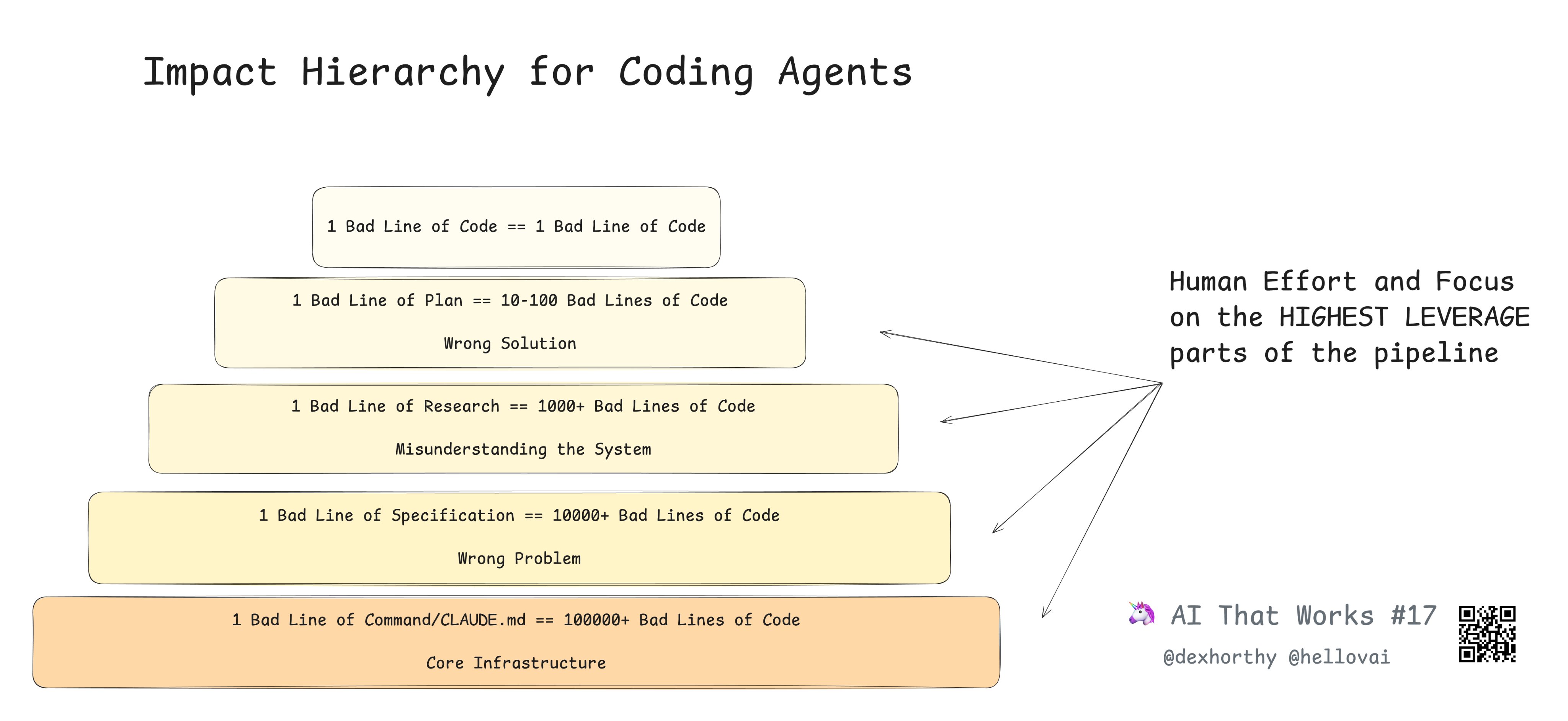 Quelle: dexhorthy auf X
Quelle: dexhorthy auf X
(wenn vielleicht auch etwas überspitzt)
2. Präzises Prompting
Dennoch ist es ebenfalls relevant, Prompts richtig zu formulieren, für bessere Ergebnisse, daher auch hier einige Tipps und Techniken:
- Sei spezifisch, aber nicht übermäßig “verbose”, wenn das Ziel klar ist:
- Tagge Dateien mit
@dir/file(Auto-Vervollständigung) - Schließe Informationen ein, die du bereits kennst
- Verwende
read in fullfür größere Dateien mit vielen relevanten Details
- Tagge Dateien mit
- Schreibe Prompts (zuerst) in einem Editor für komplexe Aufgaben
- Frage zuerst nach einem Plan, dann nach Implementierung
3. Aufgaben aufteilen
Für komplexere Aufgaben bietet sich ein mehrschrittiger Workflow an, bei dem auch Zwischenschritte dokumentiert werden, um später wieder aufsetzen und die Arbeit auch über mehrere Sessions (mit eigenem Kontext) aufteilen zu können.
Analyze ⇒ Plan ⇒ Execute Workflow:
- Analyze-Phase:
- Lass das LLM den relevanten Code sorgfältig analysieren
- Schreibe die Analyse nach
docs/<module>.md - Überprüfe und korrigiere: Fehler beheben, Unwichtiges entfernen
/clearzum Zurücksetzen des Kontexts
- Plan-Phase (erwäge Opus 4.5 für komplexe Aufgaben):
- Lese die Analyse-Datei, erstelle einen detaillierten Plan
- Schreibe den Plan nach
docs/plans/plan1.md - Überprüfe den Plan sehr sorgfältig
- Iteriere, bis der Plan solide ist
/clearzum Zurücksetzen des Kontexts
- Execute-Phase (normalerweise Sonnet):
- Lese Analyse und Plan
- Führe die Implementierung aus
Wichtig: Für nicht-triviale Aufgaben ist diese Strukturierung entscheidend für gute Ergebnisse. Vermeide es, alles in einem Schritt zu machen.
Praxis-Beispiel: Aufgabe: Implementiere ein User-Authentifizierungs-System
- Analyze: “Analysiere die bestehende User-Verwaltung in
@src/users/und dokumentiere nachdocs/auth-analysis.md” →/clear - Plan: “Lies
@docs/auth-analysis.mdund erstelle einen detaillierten Implementierungsplan nachdocs/plans/auth-plan.md” → Review →/clear - Execute: “Lies
@docs/auth-analysis.mdund@docs/plans/auth-plan.mdund implementiere das Auth-System”
Große Kontexte managen
An dieser Stelle noch einige Tipps wie man mit längerem Kontext am besten umgeht. Idealerweise lässt man es gar nicht dazu kommen:
Kontexte klein halten (Best Practice)
- Teile Aufgaben in kleine Schritte
- Lass das LLM wichtige Infos in .md-Dateien speichern
- Nutze
/clearzwischen größeren Schritten - Vermeide es, an Kontext-Grenzen zu stoßen
Sollte dies nicht möglich sein:
Kompaktierung vermeiden
Automatische Kompaktierung (vermeiden):
- Wird ausgelöst, wenn der Kontext voll ist
- LLM fasst den Gesprächsverlauf zusammen
- Verliert oft wichtige Informationen
- Kann irrelevante/widersprüchliche Infos aufrufen
Manuelle Kompaktierung (bevorzugt, wenn nötig):
- Bitte das LLM, alle wichtigen Informationen nach
docs/${feature}-status.mdzu schreiben - Überprüfe die Status-Datei auf Korrektheit und Vollständigkeit
- Bitte Claude, nach Bedarf zu aktualisieren/zu korrigieren
/cleardie Sitzung- Starte neu mit der Status-Datei
- Möchte man keine temporären Zusammenfassungen erstellen, kann man
/compactauch manuell mit zusätzlichen Anweisungen aufrufen, um die Qualität der Zusammenfassung zu verbessern.
Wann kompaktieren
- Überwache Kontext-Nutzung mit dem
/context-Kommando - Erwäge manuelle Kompaktierung bei ~10-15% verbleibend
- Besser: Vermeide es, diesen Punkt durch gute Planung zu erreichen
Kontextschonung
Es gibt auch einige Techniken, um weniger unnötige Tokens im aktuellen Arbeitskontext zu haben:
- Nutze
/rewind, wenn es offensichtlich in die falsche Richtung läuft, um zu einem früheren Stand zurückzukehren (auch mit optionalem Rollback von Änderungen durch Claude)- Tipp: Es kann Sinn machen zu analysieren, was schief gelaufen ist und den Prompt umzuformulieren, z.B. mit Dingen, die Claude nicht tun soll.
- Sub-Agents können viele Tokens sparen:
- Test-Läufe: Statt 50.000+ Tokens an Test-Output landen nur Ergebnisse im Kontext
- File-Suchen: Nur Fundstellen statt aller durchsuchten Dateien
- Code-Analysen: Nur Zusammenfassung statt kompletter Code-Dump
- Verwendung: Claude startet automatisch Sub-Agents bei komplexen Aufgaben
Anmerkung: Dies sind Techniken, um weniger Tokens im aktuellen Kontext zu haben, helfen aber nicht bei Kostensenkung! Die Tokens werden an anderer Stelle verbraucht.
Qualität sicherstellen / AI Slop vermeiden
Auch mit dem besten Kontextmanagement machen Claude und Co. weiterhin Fehler, halten sich nicht an Anweisungen, oder produzieren einfach suboptimalen Code, daher gilt weiterhin:
Du bist verantwortlich für Deinen Code!
Ob dein Code – mit Agentenunterstützung produziert oder nicht – den Anforderungen genügt, musst du entscheiden. Wenn dein Agent den Code schreibt, solltest du ihn zuerst überprüfen, bevor du andere damit beauftragst.
Wichtige Erkenntnisse
Abschließend noch einmal einige der wichtigsten Punkte zusammengefasst:
- Optimiere CLAUDE.md sorgfältig
- Widersprüche sind sehr schlecht für die Output-Qualität
- Minimal aber umfassend ist das Ziel
- Halte Kontext minimal aber umfassend
- Teile Aufgaben: Analyze ⇒ Plan ⇒ Execute
- Schreibe .md-Dateien,
/clearzwischen Schritten - Bevorzuge manuelle über automatische Kompaktierung
- Prompte präzise
- Schließe bekannte Informationen ein
- Nutze
@zum Taggen von Dateien - Strukturiere komplexe Anfragen
- Überwache Kontext-Nutzung
- Nutze
/contextzur Überprüfung der Auslastung - Plane um Kontext-Grenzen herum
- Warte nicht bis “Context Anxiety” einsetzt
- Nutze
Nützliche Kommandos
/context- Zeigt Kontext-Auslastung und Aufschlüsselung/clear- Startet neu mit leerem Kontext (behält CLAUDE.md)/compact- Löst Auto-Kompaktierung aus, hier können zusätzliche Anweisungen gegeben werden, um eine bessere Zusammenfassung zu bekommen/rewind- Spult zu früherer Nachricht zurück (verwerfe spätere Interaktionen)/init- Erstellt initiale CLAUDE.md für Projekt/cost- Zeige Kosten der aktuellen Sitzung (mit Vertex)claude -c- Setze letzte Sitzung fort (Command Line)claude -r- Wähle eine Sitzung zum Fortsetzen (Command Line)
Ressourcen
Einige nützliche Artikel mit weiteren Informationen:
- Effective Context Engineering for AI Agents (Anthropic)
- Claude Code Dokumentation: Best Practices
- I can’t sleep gud anymore - A Practical Guide to Agentic Computing - Mario Zechner (Blog Post)
- Claude Code: Common Workflows
Haben Sie Fragen zum Context Management oder möchten Sie Best Practices für Ihr Team etablieren? Kontaktieren Sie uns – wir unterstützen Sie gerne beim effektiven Einsatz von AI-Agents in Ihrer Entwicklung!
Die in diesem Artikel präsentierten Informationen basieren unter anderem auf dem Vortrag “Agentic Engineering with Claude Code” von Dr. Andreas Wundsam.
Hinweis: Die Technologie entwickelt sich schnell – überprüfe immer die aktuelle Dokumentation für die neuesten Best Practices und Fähigkeiten von Modellen.