Eigenes Domainwissen mithilfe von KI einfach nutzbar machen
In diesem Artikel zeigen wir eine Möglichkeit auf, eigenes Domainwissen mit Hilfe von LLMs (Large Language Models – Große Sprachmodelle) und RAG (Resource Augmented Generation) besser zugänglich zu machen. Wir möchten Sie dazu motivieren RAG zu nutzen und wir erläutern was genau RAG ist und wie eine RAG-Pipline aussieht. In einem Folgeartikel geben wir auch einige Hinweise für die Umsetzung, sowohl was die Vorbereitung der Daten betrifft, als auch die Implementierung und Konfiguration.
Was ist RAG (Resource Augmented Generation)?
RAG steht für Resource Augmented Generation und beschreibt einen Ansatz, bei dem ein Sprachmodell (LLM) während der Laufzeit gezielt mit zusätzlichen, externen Informationen versorgt wird. Im Gegensatz zu einem rein statischen LLM, das nur mit dem Wissen aus seinem Training antwortet, kann ein RAG-System auf aktuelle oder sehr spezifische Daten zugreifen — zum Beispiel auf interne Dokumentationen, Wikis oder Notizen. So wird die Qualität und Relevanz der generierten Antworten deutlich erhöht, ohne dass das Modell selbst neu trainiert oder feinjustiert werden muss.
Warum lokale KI?
Immer mehr Unternehmen und Einzelpersonen wollen KI nutzen, um mit ihren eigenen Daten zu arbeiten — und das aus gutem Grund. Oft liegen wichtige Informationen über mehrere Systeme verstreut, in unstrukturierten Formaten wie PDFs, E-Mails oder Notizen. Herkömmliche Suchfunktionen sind dabei häufig unpräzise, langsam oder unflexibel. Eine KI-gestützte Frage-Antwort-Interaktion kann hier völlig neue Möglichkeiten eröffnen: Statt umständlich Schlagwörter zu erraten, stellt man einfach seine Frage in natürlicher Sprache und bekommt eine präzise Antwort direkt aus dem eigenen Wissensbestand.
Doch warum sollte man das Ganze lokal betreiben? Ganz einfach: Wer sensible oder vertrauliche Daten verarbeitet, möchte diese nicht ohne Not an Dritte übermitteln. Ein lokales Setup schützt die Datenhoheit und vermeidet unnötige Abhängigkeiten von externen Cloud-Diensten. Hinzu kommt: Wer ohnehin über eigene Hardware verfügt, kann so sogar Kosten sparen, insbesondere bei regelmäßigem oder großvolumigem Einsatz.
Und warum RAG? Große Sprachmodelle (LLMs) sind zwar leistungsfähig, aber aus dem Stand auf spezifische Inhalte zu trainieren ist teuer, zeitaufwendig und erfordert oft spezielles Know-how. Auch ein Fine-Tuning bestehender Modelle ist ressourcenintensiv und erfordert meist viele Experimente. Mit Resource Augmented Generation lässt sich dieses Problem für viele Anwendungsfälle eleganter lösen: Das Modell bleibt allgemein trainiert, aber wird in Echtzeit mit den eigenen Daten angereichert. So verbindet man die Stärke eines LLMs mit aktuellem, relevantem Wissen — ohne das Rad neu zu erfinden.
Wie funktioniert RAG?
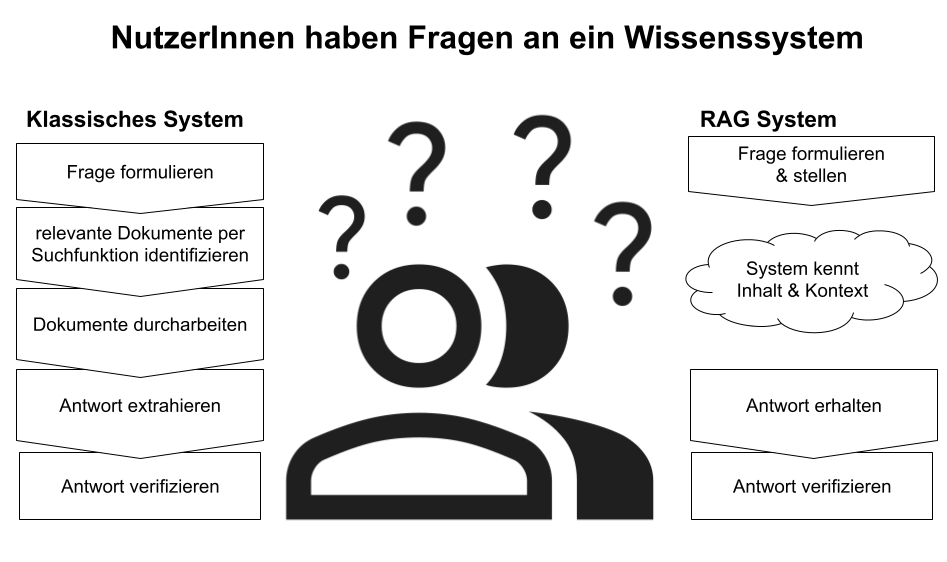
Das Grundprinzip ist einfach: Das LLM beantwortet eine Nutzerfrage nicht nur basierend auf seinem allgemeinen Weltwissen, sondern bezieht relevante Inhalte aus einer externen Wissensquelle ein. Damit bleibt das Modell flexibel, während gleichzeitig sichergestellt ist, dass die Antworten auf dem aktuellen Stand und kontextbezogen sind.
Im Unterschied zu einem klassischen System können Fragen direkt gestellt und mit Hilfe des Domainwissens direkt relevante Antworten vom System geliefert werden.
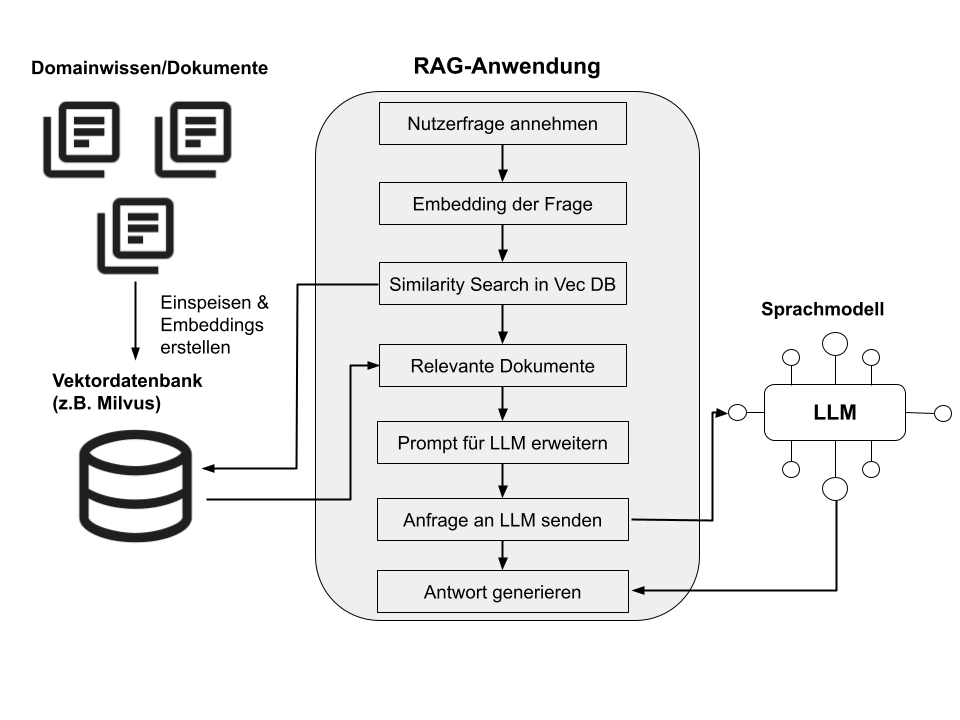
Wie sieht eine typische RAG-Pipeline aus?
Eine RAG-Pipeline besteht meist aus mehreren Schritten:
- Datenaufbereitung: Zunächst werden die eigenen Daten in eine durchsuchbare Form gebracht — typischerweise durch die Umwandlung in Vektoren (Embeddings), die dann in einer Vektordatenbank gespeichert werden. So lassen sich auch unstrukturierte Texte effizient abfragen.
- Abruf relevanter Inhalte: Bei einer Anfrage wird der eingegebene Text ebenfalls in einen Vektor umgewandelt und mit den gespeicherten Vektoren verglichen. So werden über Similarity Search die Dokumente gefunden, die der Anfrage am ähnlichsten sind.
- Erweiterung des LLM-Kontexts: Die gefundenen Informationen werden anschließend in den Prompt (also den Kontext) der LLM-Anfrage eingefügt. Das Modell generiert daraufhin eine Antwort, die sowohl sein trainiertes Weltwissen als auch die spezifischen Inhalte berücksichtigt.
- (Optional) Synthese mehrerer Suchergebnisse: Manche Pipelines kombinieren mehrere passende Treffer oder führen sogar Zwischenschritte aus, um eine besonders konsistente und vollständige Antwort zu erzeugen. So lassen sich auch komplexere Fragen abdecken, die verschiedene Aspekte verbinden.
Warum ist dieser Ansatz so interessant?
Der große Vorteil von RAG liegt in der Flexibilität: Statt ein LLM aufwändig für jedes neue Daten-Update anzupassen, bleibt der Abruf-Mechanismus dynamisch. Neue Inhalte können einfach in die Vektordatenbank aufgenommen werden, ohne dass das Modell selbst verändert werden muss. Das spart Zeit, Kosten und reduziert die technischen Hürden erheblich.
Einige beispielhafte Anwendungsfälle für RAG
Im Folgenden zeigen wir einige typische Einsatzszenarien für RAG-basierte Anwendungen. Sie sollen dabei helfen einzuschätzen, ob und wie sich der Ansatz sinnvoll auf Ihre eigenen Anwendungsfälle übertragen lässt. Wie bei allen KI-Systemen gilt jedoch: Je sensibler der Kontext, desto wichtiger ist es, die generierten Antworten sorgfältig zu prüfen und gegebenenfalls durch Fachwissen abzusichern.
Interne Wissensdatenbanken durchsuchen:
Technische Dokumentationen, Protokolle oder interne Handbücher können in eine Vektordatenbank eingespeist werden. Ein RAG-System beantwortet Fragen dazu viel präziser als eine klassische Volltextsuche.
Support-Assistenz für Kundenteams:
Kundensupport-MitarbeiterInnen können über natürliche Sprache Lösungen in FAQs, Ticket-Logs oder Produktinformationen finden — ohne sich durch mehrere Systeme klicken zu müssen.
Schnelle Einarbeitung neuer Mitarbeitender:
Neue Teammitglieder können sich selbstständig Wissen erschließen, indem sie in natürlicher Sprache Fragen stellen und dabei aktuelle, interne Inhalte als Antwortbasis nutzen.
Forschung und Entwicklung:
Forschungsinhalte, Berichte und Notizen werden gebündelt durchsuchbar, wodurch sich Hypothesen schneller prüfen oder neue Verbindungen erkennen lassen.
Fazit
In diesem Artikel haben wir aufgezeigt wie RAG eine elegante Brücke zwischen leistungsfähiger KI und individuellem Fachwissen bietet – ganz ohne aufwändige Trainingsprozesse oder riskante Cloud-Abhängigkeiten. Wer eigene Daten effizient und sicher zugänglich machen will, findet in RAG einen äußerst flexiblen Ansatz, der sich gut an bestehende Strukturen anpassen lässt. Im nächsten Beitrag geben wir praxisnahe Hinweise, wie Sie eine eigene RAG-Pipeline aufbauen können – von der Datenaufbereitung, über Integrationstipps, bis zu unseren Erfahrungen bei der Feinkonfiguration. Bleiben Sie dran!