Umleitungen umleiten - Wie man Returncodes und Daten aus Linux-Pipes herausfischt
Neulich hatte ich das Problem, dass der Buildprozess eines “gewachsenen”, sehr umfangreichen Projektes bei manchen der auftretenden Compilefehler anstatt direkt mit einer Meldung abzubrechen einfach weiter lief.
Es stellte sich heraus, dass die eigentlich sehr praktische Nutzung von Ein- und Ausgabeumleitungen, sogenannten “Pipes”, in manchen Situationen nicht das gewünschte Verhalten zeigt.
In meinem Fall war es das zusätzliche Schreiben der ausgegebenen Meldungen des C++-Compilers in eine Protokolldatei, also das in Build-Skripten und Makefiles durchaus übliche Pattern
file.o: file.cpp
c++ .... file.cpp 2>&1 | tee $LOGFILE
Obwohl der C++-Compiler in diesem Fall bei Fehlern einen negativen Exit-Code ausgibt, wird dieser vom
aufrufenden make nicht erkannt. Der Exit-Code der Befehlskette wird nämlich durch den Exit-Code
des letzten Elementes definiert. Das ist hier aber der tee-Befehl, so daß der Returncode
des Compilers verloren geht.
Wir müssen also den Exit-Code des ersten Kommandos der Verarbeitungskette irgendwie ausleiten.
Doch schauen wir uns zunächst einmal generell das Konstrukt der Eingabe- und Ausgabeumleitung in Unix-Shells an.
Die Familie der Unix-Betriebssysteme und damit heutzutage insbesondere alle Linux-Systeme sind von
Beginn an als ein flexibler Baukasten für Softwareentwickler konzipiert worden.
Eine der Grundideen ist hierbei die sogenannte Pipe, das Leiten eines (Text-) Datenstroms durch eine hintereinander
geschaltete Kette mehrerer kleiner hochspezialisierter Programme, die jeweils “nur” eine Sache können, diese
aber meist besonders gut.
Hierzu hängt man die Programme mit Hilfe des Pipe-Operators | hintereinander.
worker | filter
Der Pipe-Operator | bewirkt, dass die (Standard-) Ausgabe (Kanal 1) des ersten Programms als
(Standard-) Eingabe (Kanal 0) des nächsten dient.
Dabei kann es beliebig viele Verarbeitungsschritte geben, beispielsweise
worker | filter1 | filter2 | filter3 | filter4
Um die Frage zu beantworten, welche Unterverzeichnisse dieser Seite die meisten Markdown-Dateien enthalten, könnte beispielsweise folgende Befehlskette verwendet werden:
42ways$ find . -name '*.md' | cut -d '/' -f 2 | sort |
pipe> uniq -c | sort -r
32 _posts
6 pages
2 _site
2 _drafts
1 presentations
1 index.md
1 README.md
Doch zurück zu unserem Compiler-Beispiel:
c++ .... file.cpp 2>&1 | tee $LOGFILE
Die ausführende Shell gibt am Ende den Returncode des letzten Programms, in unserem Fall tee zurück.
Und der ist in diesem Fall in der Regel 0, also der Status OK (außer die Datei $LOGFILE kann nicht
geschrieben werden).
Wir möchten aber gerne den Returncode des Compileraufrufs c++ haben.
Einige Shells, wie beispielsweise die bash kennen hierfür eine spezielle Variable PIPESTATUS, die in einem
Array die Returncodes aller in der Pipeline vorkommenden Befehle enthält.
Es gibt aber auch eine Lösung des Problems, die in allen POSIX-Shells funktioniert.
Neben den Kanälen 0 (stdin), 1 (stdout) und 2 (stderr) können wir nämlich weitere IO-Kanäle verwenden.
Damit können wir beliebige Informationen an der “normalen” Pipe vorbei leiten und später weiter verarbeiten.
In unserem konkreten Beispiel sieht das dann so aus:
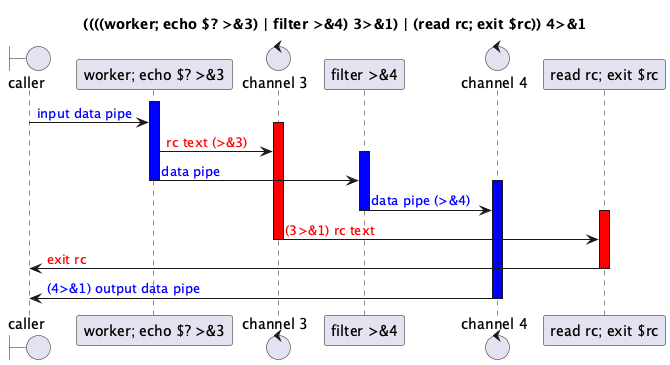
((((c++ .... file.cpp 2>&1; echo $? >&3) | tee $LOGFILE >&4) 3>&1) | (read rc; exit $rc)) 4>&1
OOPS. Ganz schön unübersichtlich.
Aber ganz so schlimm ist es gar nicht. Schritt für Schitt passiert hier Folgendes:
- Die Ausgabe von
stderr(Kanal 2) desc++-Compilers wird durch2>&1nachstdout(Kanal 1) umgeleitet (damit beides im$LOGFILElandet) - Anschließend wandeln wir den Returncode des Compilers in eine Textausgabe um und schicken diese in den Kanal 3 (
echo $? >&3) - Im nächsten Schritt duplizieren wir die Standardausgabe mittels
tee, um unser Logfile zu schreiben. Da wir anschließend den Kanal 1 für die folgende Pipe wieder brauchen, leiten wir dessen Ausgabe zunächst mal auf Kanal 4 um (>&4) - Nun ist der Zeitpunkt gekommen, unseren auf Kanal 3 umgeleiteten Returncode in die Standardausgabe zu schreiben (
3>&1) - Der nächste Schritt liest diesen Wert nun in einer weiteren Sub-Shell ein und gibt ihn als Returncode an die aufrufende Shell (
read rc; exit $rc). Damit geben wir den umgeleiteten Returncode des Compilers nun als Returncode des letzten Befehls in der Kette zurück - Schließlich leiten wir den über Kanal 4 umgeleiteten Ausgabestream wieder dahin um, wo er hin gehört, nämlich auf Kanal 1 (
4>&1)
Hier noch mal eine Darstellung des Ganzen als Sequenzdiagramm. Die Datenkanäle sind dabei blau, die Umleitung des Returncodes rot dargestellt.
Und nun Happy Pilelining